This is a continuation of Part 1, so if you haven’t read that already, you should do so now.
goimports
The idea of goimports is that every time you save a file, it will automatically update all of your imports, so you don’t have to. This can save a lot of time. Kudos to @bradfitz for taking the time to build this nifty tool.
go get goimports with:
1
$ go get golang.org/x/tools/cmd/goimports
Continuing on previous .emacs in Part 1, update your ~/.emacs.d/init.el to:
1234567891011121314
(defun my-go-mode-hook ()
; Use goimports instead of go-fmt
(setq gofmt-command "goimports")
; Call Gofmt before saving
(add-hook 'before-save-hook 'gofmt-before-save)
; Customize compile command to run go build
(if (not (string-match "go" compile-command))
(set (make-local-variable 'compile-command)
"go build -v && go test -v && go vet"))
; Godef jump key binding
(local-set-key (kbd "M-.") 'godef-jump)
(local-set-key (kbd "M-*") 'pop-tag-mark)
)
(add-hook 'go-mode-hook 'my-go-mode-hook)
Restart emacs to force it to reload the configuration
Testing out goimports
Open an existing .go file that contains imports
Remove one or more of the imports
Save the file
After you save the file, it should re-add the imports. Yay!
Basically any time you add or remove code that requires a different set of imports, saving the file will cause it to re-write the file with the correct imports.
The Go Oracle
The Go Oracle will blow your mind! It can do things like find all the callers of a given function/method. It can also show you all the functions that read or write from a given channel. In short, it rocks.
Here’s what you need to do in order to wield this powerful tool from within Emacs.
Go get oracle
1
go get golang.org/x/tools/cmd/oracle
Update emacs config
Update your ~/.emacs.d/init.el to:
12345678910111213141516
(defun my-go-mode-hook ()
; Use goimports instead of go-fmt
(setq gofmt-command "goimports")
; Call Gofmt before saving
(add-hook 'before-save-hook 'gofmt-before-save)
; Customize compile command to run go build
(if (not (string-match "go" compile-command))
(set (make-local-variable 'compile-command)
"go generate && go build -v && go test -v && go vet"))
; Go oracle
(load-file "$GOPATH/src/golang.org/x/tools/cmd/oracle/oracle.el")
; Godef jump key binding
(local-set-key (kbd "M-.") 'godef-jump)
(local-set-key (kbd "M-*") 'pop-tag-mark)
)
(add-hook 'go-mode-hook 'my-go-mode-hook)
Restart Emacs to make these changes take effect.
Get a test package to play with
This package works with go-oracle (I tested it out while writing this blog post), so you should use it to give Go Oracle a spin:
1
go get github.com/tleyden/checkers-bot-minimax
Set the oracle analysis scope
From within emacs, open $GOPATH/src/github.com/tleyden/checkers-bot-minimax/thinker.go
You need to tell Go Oracle the main package scope under which you want it to operate:
M-x go-oracle-set-scope
it will prompt you with:
Go oracle scope:
and you should enter:
github.com/tleyden/checkers-bot-minimax and hit Enter.
Nothing will appear to happen, but now Go Oracle is now ready to show it’s magic. (note it will not autocomplete packages in this dialog, which is mildly annoying. Make sure to spell them correctly.)
Important: When you call go-oracle-set-scope, you always need to give it a main package. This is something that will probably frequently trip you up while using Go Oracle.
Use oracle to find the callers of a method
You should still have the $GOPATH/src/github.com/tleyden/checkers-bot-minimax/thinker.go file open within emacs.
Position the cursor on the “T” in the Think method (line 13 of thinker.go):
And then run
1
M-x go-oracle-callers
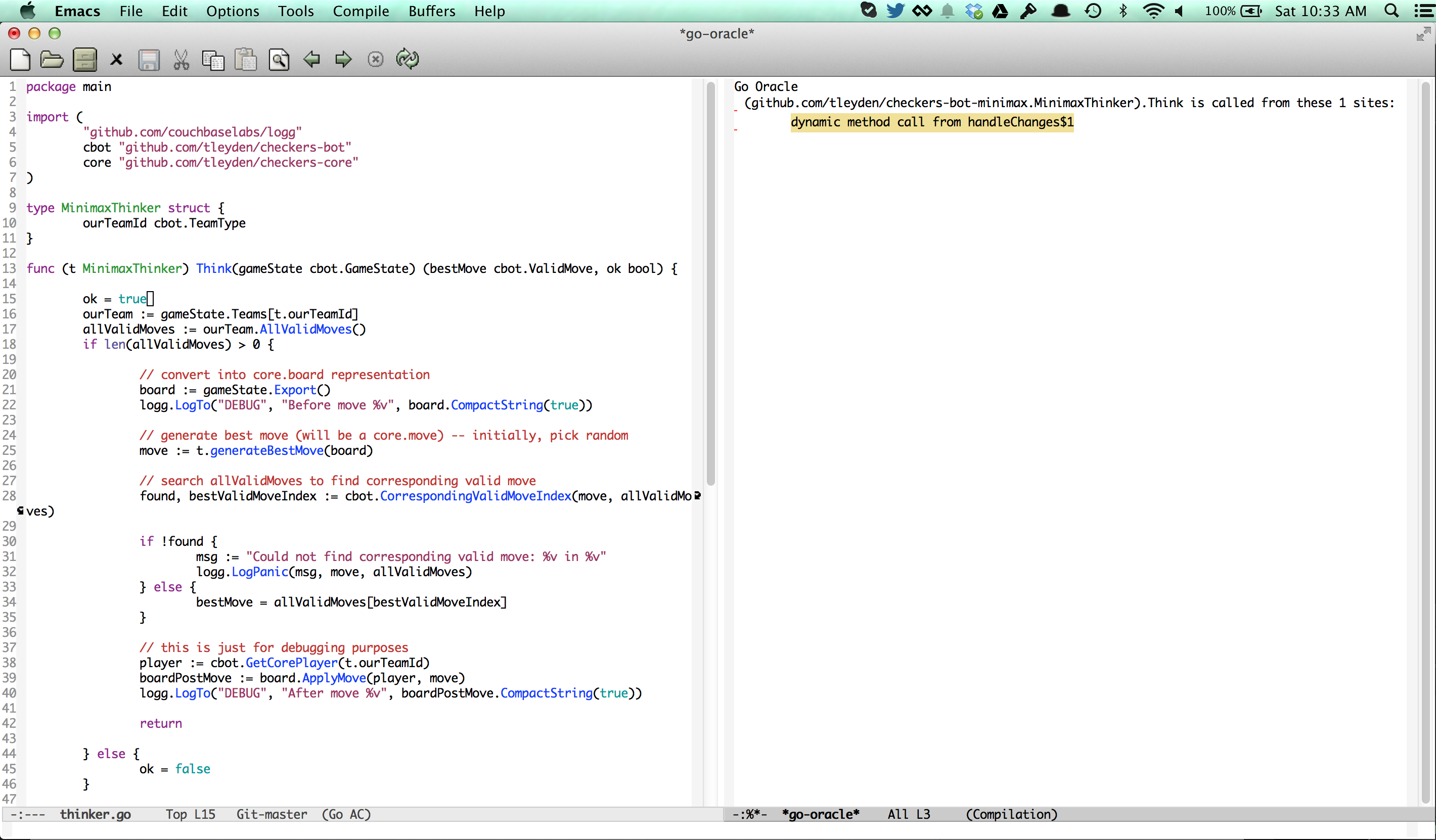
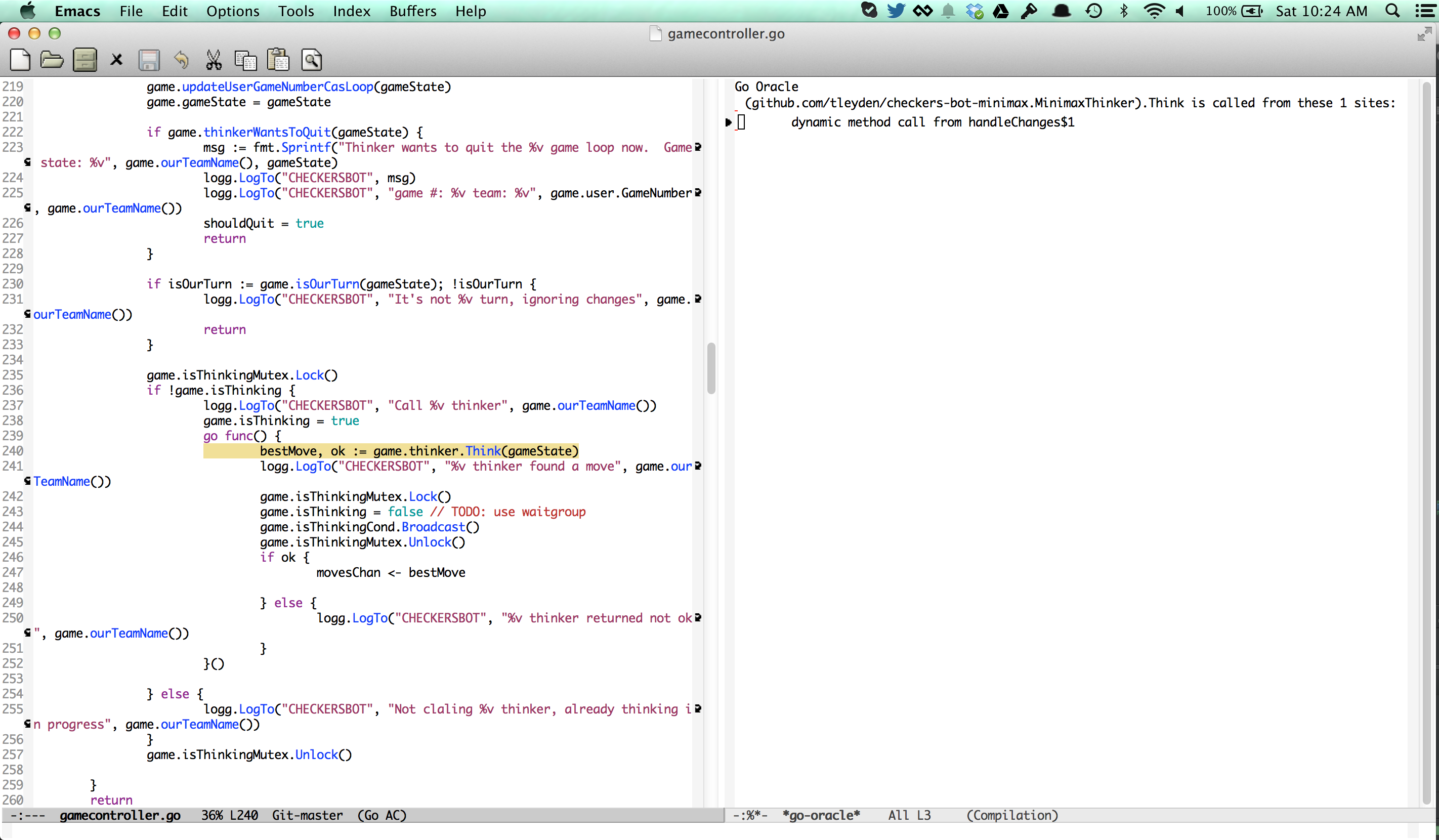
Emacs should open a new buffer on the right hand side with all of the places where the Think method is called. In this case, there is only one place in the code that calls it:
To go to the call site, position your cursor on the red underscore to the left of “dynamic method call” and hit Enter. It should take you to line 240 in gamecontroller.go:
Note that it actually crossed package boundaries, since the called function (Think) was in the main package, while the call site was in the checkersbot package.
If you got this far, you are up and running with The Go Oracle on Emacs!
Now you should try it with one of your own packages.
This is just scratching the surface — to get more information on how to use Go Oracle, see go oracle: user manual.
Troubleshooting
If you get this error when running go-oracle-callers:
123456789
Go Oracle
Agreeing to the Xcode/iOS license requires admin privileges, please re-run as root via sudo.
cgo failed: [go tool cgo -objdir /var/folders/2j/cp3qdxqs72g99l49h40f9p7m0000gn/T/net_C392209343 -- -I /var/folders/2j/cp3qdxqs72g99l49h40f9p7m0000gn/T/net_C392209343 cgo_bsd.go cgo_resnew.go cgo_sockold.go cgo_unix.go]: exit status 1
Agreeing to the Xcode/iOS license requires admin privileges, please re-run as root via sudo.
... etc
Restart emacs and run M-x package-list-packages and you should see it contacting http://melpa.milkbox.net and you should also see lot of packages listed as being from the melpa archive.
Install go-mode
Run M-x package-install and when prompted, enter go-mode and hit enter.
Restart Emacs and open a .go file, you should see the mode as “Go” rather than “Fundamental”.
For a full description of what go-mode can do for you, see Dominik Honnef’s blog, but one really useful thing to be aware of is that you can quickly import packages via C-c C-a
Update Emacs path to find godoc
Run M-x package-install and enter exec-path-from-shell
I got this warning:
12345678
Compiling file /Users/tleyden/.emacs.d/elpa/exec-path-from-shell-20160112.2246/exec-path-from-shell-pkg.el at Sat Feb 6 18:20:55 2016
Entering directory `/Users/tleyden/.emacs.d/elpa/exec-path-from-shell-20160112.2246/'
Compiling file /Users/tleyden/.emacs.d/elpa/exec-path-from-shell-20160112.2246/exec-path-from-shell.el at Sat Feb 6 18:20:55 2016
In exec-path-from-shell-setenv:
exec-path-from-shell.el:189:11:Warning: assignment to free variable
`eshell-path-env'
Restart emacs.
Update Emacs config for godoc
It’s really useful to be able to able to pull up 3rd party or standard library docs from within Emacs using the godoc tool.
PATH
Add the following to your ~/.emacs.d/init.el file so that it gets the PATH environment:
(replace the above path to the absolute path to the directory where you store your Go code)
After doing this step, you should be able to run M-x godoc and it should be able to autocomplete paths of packages. (of course, you may want to go get some packages first if you don’t have any)
Automatically call gofmt on save
gofmt reformats code into the One True Go Style Coding Standard. You’ll want to call it every time you save a file.
Now restart emacs, and when you start typing the name of a field in a struct it will popup something that looks like this:
Note that is more “go-aware” than the default auto-complete functionality.
Customize the emacs compile command to run go build
It’s convenient to be able to run M-x compile to compile and test your Go code from within emacs.
To do that, edit your ~/.emacs.d/init.el and replace your go-mode hook with:
123456789101112
(defun my-go-mode-hook ()
; Call Gofmt before saving
(add-hook 'before-save-hook 'gofmt-before-save)
; Customize compile command to run go build
(if (not (string-match "go" compile-command))
(set (make-local-variable 'compile-command)
"go build -v && go test -v && go vet"))
; Godef jump key binding
(local-set-key (kbd "M-.") 'godef-jump)
(local-set-key (kbd "M-*") 'pop-tag-mark)
)
(add-hook 'go-mode-hook 'my-go-mode-hook)
After that, restart emacs, and when you type M-x compile, it should try to execute go build -v && go test -v && go vet instead of the default behavior. On some projects, you might also want to run go generate before go build
Power tip: you can jump straight to each compile error by running C-x `. Each time you do it, it will jump to the next error.
Couchbase Mobile just announced it’s 1.0 release today.
What is Couchbase Mobile?
Couchbase Lite is an open source iOS/Android NoSQL DB with built-in sync capability.
Couchbase Mobile refers to the “full stack” solution, which includes the (also open source) server components that Couchbase Lite uses for sync.
To give a deeper look at what problem Couchbase Mobile is meant to solve, let me tell you the story of how I came to discover Couchbase Lite as a developer. In my previous startup, we built a mobile CRM app for sales associates.
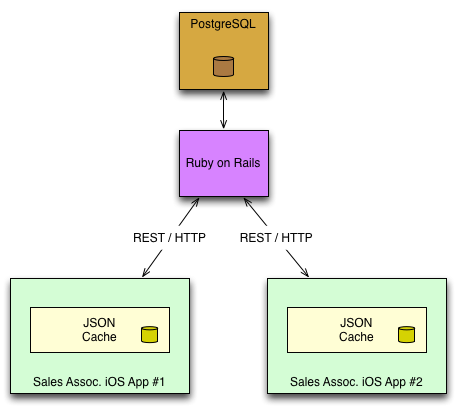
The very first pilot release of the app, the initial architecture was:
It was very simple, and the server was almost the Single Point of Truth, except for our JSON caching layer which had a very short expiry time before it would refetch from the server. The biggest downside to this architecture was that it only worked well when the device had a fast connection to the internet.
But there was another problem: getting updates to sync across devices in a timely manner. When sales associate #1 would update a customer, sales associate #2 wouldn’t see the change because:
How does the app for sales associate #2 know it needs to “re-sync” the data?
How will the app know that something changed on the backend that should cause it to invalidate that locally cached data?
We realized that the data sync between the devices was going to be a huge issue going forward, and so we decided to change our architecture to something like this:
So the app would be displaying what’s stored in the Core Data datastore, and we’d build a sync engine component that would shuttle data bidirectionally between Core Data and the backend server.
That seemed like a fine idea on paper, except that I refused to build it. I knew it would take way too long to build, and once it was built it probably would entail endless debugging and tuning.
Instead, after some intense debate we embarked on a furious sprint to convert everything over to Couchbase Lite iOS. We ended up with an architecture like this:
It was similar in spirit to our original plans, except we didn’t have to build any of the hard stuff — the storage engine and the sync was already taken care of for us by Couchbase Lite.
(note: there were also components that listened for changes to the backend server database and fired off emails and push notifications, but I’m not showing them here)
After the conversion ..
On the upside
Any updates to customer data would quickly sync across all devices.
Our app still worked even when the device was completely offline.
Our app was orders of magnituted faster in “barely connected” scenarios, because Couchbase Lite takes the network out of the critical path.
Our data was now “document oriented”, and so we could worry less about rolling out schema changes while having several different versions of our app out in the wild.
On the downside
We ran into a few bizarre situations where a client app would regurgitate a ton of unwanted data back into the system after we’d thought we’d removed it. To be fair, that was our fault, but I mention it because Couchbase Lite can throw you some curve balls if you aren’t paying attention.
Certain things were awkward. For example for our initial login experience, we had to sync the data before the sales associate could login. We ended up re-working that to have the login go directly against the server, which meant that logging in required the user to be online.
When things went wrong, they were a bit complicated to debug. (but because Couchbase Lite is Open Source, we could diagnose and fix bugs ourselves, which was a huge win.)
So what can Couchbase Lite do for you?
Sync Engine included, so you don’t have to build one
If I had to sum up one quick elevator pitch of Couchbase Lite, it would be:
If you find that you’re building a “sync engine” to sync data from your app to other instances of your app and/or the cloud, then you should probably be building it on top of Couchbase Lite instead of going down that rabbit hole — since you may never make it back out.
Your app now works well in offline or occasionally connected scenarios
This is something that users expect your app to handle. For example, if I’m on the BART going from SF –> Oakland and have no signal, I should still be able to read my tweets, and even send new tweets that will be queued to sync once the device comes back online.
If your app is based on Couchbase Lite, you essentially get these features for free.
When you load tweets, it is loaded from the local Couchbase Lite store, without any need to hit the server.
When you create a new tweet, you just save it to Couchbase Lite, and let it handle the heavy lifting of getting that pushed up to the server once the device is back online.
Your data model is now Document Oriented
This is a double edged sword, and to be perfectly honest a Document Oriented approach is not always the ideal data model for every application. However, for some applications (like CRM), it’s a much more natural fit than the relational model.
And you’ll never have to worry about getting yourself stuck in Core Data schema migration hell.
What’s the dark side of Couchbase Lite?
Queries can be faster, but they have certain limitations
With SQL, you can run arbitrary queries, irregardless if there is an index or not.
Couchbase Lite cannot be queried with SQL. Instead you must define Views, which are essentially indexes, and run queries on those views. Views are extremely fast and efficient, but if you don’t have a view, you can’t run a query, period.
For people who are used to SQL, defining lower level map/reduce views takes some time to wrap your head around.
Complex queries can get downright awkward
Views are powerful, but they have their limitations, and if your query is complex enough, you may end up needing to write multiple views and coalescing/sorting the data in memory.
It’s not a black box, but it is complicated.
The replication code in Couchbase Lite is complicated. I know, because I’ve spent a better part of the last year staring at it.
As an app developer, you are putting your trust that the replication will work as you would expect and that it will be performant and easy on the battery.
The good news is that it’s 100% open source under the Apache 2 license. So you can debug into it, send issues and pull requests to our github repo, and even maintain your own fork if needed.
When completed the release branch would be merged into both the master and stable branches, the commit on the stable branch would be tagged with a release tag (eg, 1.0.0).
The release branch would be discarded after being merged back into master and stable.
Release branches would be named “release/xxx”, where xxx is the target release tag for that release. Eg, “release/1.0.0”.
Release branches should only have bugfixes related to the release being committed to them. All other changes should be on feature branches or the master branch, isolated from the release process.
Release branches would help avoid making developers having to “double-commit” bugfixes related to a release to both the release branch and the master branch — because the release branch will be merged into master at the time of release, they only need to commit the fix to the release branch.
Release branches should be periodically merged back into the master branch if they run longer than normal (eg, if it was expected to last 3 weeks and ended up lasting 8 weeks), rather than waiting until the time of release. This will reduce the chance of having major merge conflicts trying to merge back into master.
When a release is ready to be tagged, if the release branch does not easily merge into master, it is up to the dev lead on that team to handle the merge (not the build engineer). In this case, the build engineer should not be blocked, because the merge into stable will be a fast-forward merge, and so the release can proceed despite not having been merged into master yet.
Support Branches
Support branches would be created “on demand” when requested by customers who are stuck on legacy releases and are not able to move forward to current releases, but need security and other bug fixes.
Support branches should be avoided if possible, by encouraging customers to move to the current release, because they create extra work for the entire team.
Support branches would follow a similar naming scheme and would be named “support/xxx”, where xxx is the release tag from which they were branched off of. Eg, “support/1.0.1”.
Support branches are essentially dead-end branches, since their changes would unlikely need to be merged back into master (or stable) as the support branch contains “ancient code” and most likely those fixes would already have been integrated into the codebase.
If a customer is on the current release, then there is no need to create a support branch for their required fix. Instead, a hotfix branch should be used and a new release tag should be created.
Hotfix Branches
Hotfix branches would branch off of the stable branch, and be used for minor post-release bugfixes.
Hotfix branches would be named “hotfix/xxx”, where xxx might typically be an issue id. Once their changes have been merged into master and stable, they should be deleted.
Hotfix branches are expected to undergo less QA compared to release branches, and therefore are expected to contain minimum changes to fix showstopper bugs in a release. The changes should not include refactoring or any other risky changes.
If it’s being branched off the master branch, it’s not a hotfix branch. Hotfixes are only branched off the stable branch.
Hotfix branches should verified on the CI server using the automated QA suite before being considered complete.
After being accepted by QA, hotfix branches are merged back into master and stable, and the latest commit on stable is tagged with a release tag. (eg, 1.0.1)
Similar to release branches, if hotfixes do not easily merge back into master, the build engineer would assign the dev lead the responsibility for completing the merge, but this should not block the release. However since hotfix branches are so short-lived, this is very unlikely to happen.
Stable Branch
The stable branch would represent the “released” mainline development.
The latest commit on stable should always correspond to the latest release tag.
All release tags should be made against commits on stable, except for those on legacy support branches.
Developers who wanted to subscribe to the latest released code would follow the stable branch.
Master Branch
The master branch would represent the “as-yet-unreleased” mainline development.
Feature Branches
All non-trivial changes should be done on feature branches and undergo code review before being merged into the master branch.
A great “best practices” for juggling git branches in a release cycle is A successful git branching model. It is also accompanied with a tool called git flow that makes it easy to implement in practice.
It does however have one major issue: many people use a different naming scheme.
Instead of:
Master – the latest “stable” branch
Development – bleeding edge development branch
a slightly more common naming pattern is:
Master – bleeding edge development branch
Stable – the latest “stable” branch
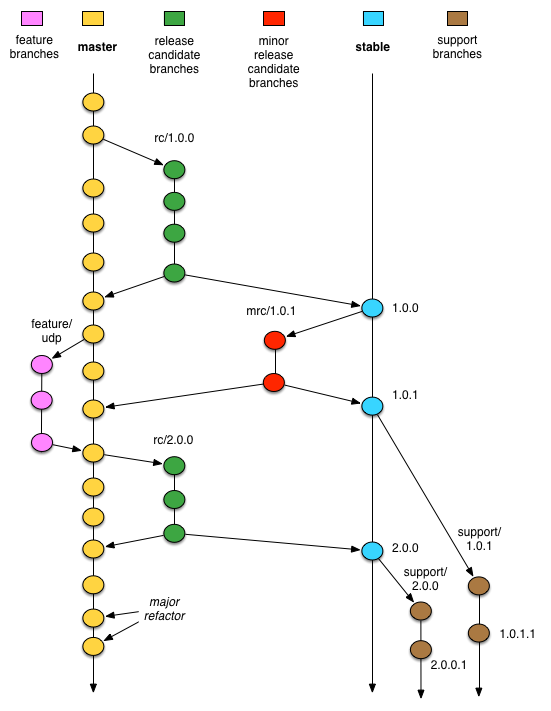
To that end, I’ve tweaked the original diagram to be.
Every branch solves a problem
The natural reaction to most people seeing this diagram is dude, that’s way too many branches, this is way more complicated than it needs to be. Actually, I’d argue that it’s minimally complex to solve the problems that these branches are designed to solve. In other words, each type of branch justifies it’s existence by the problem it’s designed to solve.
From the perspective of a library developer (in my case, Couchbase Lite for Android), here are the problems each branch is intended to solve.
Permanent and External Facing Branches
These branches are permanent, in the sense they have a continuous lifetime. They are also external, and consumers of the library would typically depend on one or both of these branches
Master
A home for the latest “feature complete” / reviewed code.
Anyone internal or external who wants to stay up to date with latest project developments needs this branch.
Stable
A home for the code that corresponds to the latest tagged release.
This branch would be the basis for post-release bugfixes, eg an external developer who finds a bug in the latest release would send a pull request against this branch.
Developers depending on this code directly in their app would likely point to this branch on their own stable branch.
Ephemeral and Internal Only Branches
These branches are emphemeral in nature, and are thrown away once they are no longer useful. Developers consuming the library would typically ignore these
FeatureX
A place for in progress features to live without de-stabilizing the master branch. Can be many of these.
Hotfix
An in progress fix would go here, where that fix is destined to be merged back into latest stable but not part of a new release that is branched off of master.
While this hotfix is in progress, since these commits are not part of a tagged release, they cannot go on stable (yet), otherwise it would be a violation of the stable branch contract that says that stable reflects the latest tagged release.
They could go directly on a “local stable” branch, which is only on the developers workstation, but that prevents sharing the branch or running CI unit tests against it, so it’s not a good solution.
NOTE: when hotfix merged, new release tagged simultaneously with a merge to stable, so the stable branch contract stays satisfied.
Release
During QA release process, need a place to QA and apply bugfixes, while isolated from destabilizing changes such as merging feature branches.
Release branch allows feature branch merging to happen concurrently on master branch, which is especially crucial if release gets delayed.
Get this spinning gopher working with Go and OpenGL on OSX Mavericks via gogl
Steps
12345678
$ brew install glfw2
$ go get -u -v github.com/tleyden/gogl
$ go get -u -v github.com/go-gl/glfw
$ cd $GOPATH/src/github.com/tleyden/gogl
$ make bindings
$ go get -u -v github.com/chsc/gogl
$ cd $GOPATH/src/github.com/tleyden/gogl/examples/gopher
$ go run gopher.go
NOTE: if pull request #37 has already been merged into gogl, then replace github.com/tleyden/gogl with https://github.com/chsc/gogl in steps above.
What are the advantages of Go against C++ or other languages?
Go has sane concurrency.
In C++ the main tool to deal with concurrency is pthreads, but making threaded programming correct is extremely difficult and error prone. Trying to make it performant by minimizing locking makes it even more challenging.
Go, OTOH, has a concept of goroutines and channels for concurrency. The idea has its roots in CSP (communicating sequential processing), and is not unlike Erlang’s style of having processes that communicating by message passing.
In Go, instead of having threads communicating by sharing memory (and locking), goroutines share memory by communicating over channels. Eg, concurrent goroutines communicate over channels, and each goroutine’s internal state is private to that goroutine. Also, concurrency and their constructs like channels are built right into the Go language, which affords many advantages over languages that have had concurrency slapped on as an afterthought.
Other Strengths
No unsafe pointer arithmetic.
Array bound checking
Write once run anywhere
Closures (eg, lambdas)
Functions are first class objects
Multiple return values
Does not have IFDEF’s, so no IFDEF hell and unmaintainable code.
Compiles blazingly fast
Gofmt – All code is uniformly formatted, making codebases much easier to read. (a la Python)
Garbage collection
Weaknesses
Lack of generics
Not quite as fast as C/C++ (partly due to GC overhead)
Integration with existing native code is a bit limited (you can’t build libraries in Go or link Go code into a C/C++ executable)
IDE support is limited compared to C/C++/Obj-C/Java
Doesn’t work with regular debugging tools because it doesn’t use normal calling conventions.
I’m about to split up the couchbase-lite android library into two parts: a pure-java and an android specific library. The android library will depend on the pure-java library.
Before going down this project refactoring rabbit hole for the real project, I decided to stub out a complete project hierarchy to validate that it was going to actually work. (I’m calling this project hierarchy “stubworld” for lack of a sillier name)
There are five projects in total, here are the two top-level projects
The projects are all self contained gradle projects and can be imported in either Android Studio or IntelliJ CE 13, and the dependencies on lower level projects are done via git submodules (and even git sub-submodules, gulp). In either top level project you can easily debug and edit the code in the lower level projects, since they use source level dependencies.
The biggest sticking point I ran into was that initially I tried to include a dependency via:
which totally broke when trying to embed this project into another parent project. The fix was to change it to use a relative path by removing the leading colon:
I’m posting this in case it’s useful to anyone who needs to do something similar, or if any Gradle / Android Studio Jedi masters have any feedback like “why did you do X, when you just could have done Y?”
The goal is to create an Objective-C class which takes an array of NSURL’s, downloads their contents asynchronously, and writes the contents of each URL to a unique file.
The class should be named URLPuller and should have the following instance methods:
- (void) downloadUrlsAsync: (NSArray*)urls
- (void) waitUntilAllDownloadsFinish
- (NSString*) downloadedPathForURL: (NSURL*)url
Here are the detailed descriptions of each method:
downloadUrlsAsync
- (void) downloadUrlsAsync: (NSArray*)urls
The urls array will contain an array of NSURL’s. The method should return immediately, eg, it’s an asynchronous API call that will run in the background.
The downloaded files can be stored in any directory, where the filename is {sha1 hash of url}.downloaded
waitUntilAllDownloadsFinish
- (void) waitUntilAllDownloadsFinish
Block until all of the URLs have been downloaded.
If this is called while there is no download in progress, it should return immediately. Otherwise, it should block until all the downloads have finished.
downloadedPathForURL
- (NSString*) downloadedPathForURL: (NSURL*)url
Return the path where the given url was downloaded to.
If the given url has not been downloaded yet, or was never requested to be downloaded, then it should return nil.
Objectives
Demonstrate that:
You can write a program that satisfies the API methods and described behavior.
You can write code that is well factored, and easy to understand.
You can clearly communicate questions (if any arise) regarding this specification.
Deliverable
Zipped Xcode project directory or a link to github repo that contains the Xcode project. It can be either an iOS or MacOS project.
Rules
You can use any available resource you can find on the Internet — eg, Stack Overflow, API docs, etc.
You may not ask questions related to the problem on Stack Overflow, IRC, etc. (eg, the Internet is “read-only”)
You cannot use any 3rd party libraries or products, you can only use classes and API’s in the standard iOS/Cocoa Objective-C runtime. If in doubt, just ask.
You are welcome to go above and beyond the call of duty in any way that you see fit, however with the constraint that you must provide the above methods with signatures exactly matching with the specification.
The good news is that it’s very easy to downgrade! Thank Google, because there is nothing more annoying than not being able to back out of an upgrade gone bad.
The last step is necessary because the dowloaded 0.3.7 Android Studio will not have an SDK directory. (Note: at this point you can also use mv instead of cp if you don’t want to use the extra disk space)